
Nachdem Tweetnest, ein Programm zur Archivierung von Tweets, seine Entwicklung eingestellt hat, bin ich schon eine ganze Weile auf der Suche nach einer Alternative.Weiterlesen
Durchsuche Archive nach
Schlagwort: Twitter
Wer ist meine Öffentlichkeit und wenn ja, wieviele

CC by-nc-nd by Fräulein Schiller (flickr)
Man sagt: „Google weiß mehr über dich als du selber“. Wenn da etwas dran ist, dann beruht das Wissen ausschließlich auf einer Datenanalyse, also auf Spuren, die unweigerlich jeder hinterlässt, der ins Internet schreibt und sei es nur in den Suchschlitz. Seit einigen Jahren versuche ich meine eigenen Daten, die ich fremden Plattformen anvertraut habe nicht nur herunterzuladen, sondern auch auszuwerten.Weiterlesen
Was 2012 war

Wir schreiben ständig ins Internet, mittlerweile sind wir uns wahrscheinlich gar nicht bewusst, was und wieviel wir dort eigentlich reinschreiben. Bevor das neue Jahr nicht mehr als solches bezeichnet werden kann, möchte ich jenseits der WordPressdaten, die an diversen Stellen veröffentlicht werden zeigen, was ich sonst noch so über mich und euch rausgefunden habe. Denn natürlich hat jede reinschrift in das Internet Auswirkungen auf eine mir zum Teil vollkommen unbekannte Leserschaft:Weiterlesen
Twauswertung des Educamps Köln #ecco12

Auswertungen gibt es solche und solche. Ich möchte mich an einer Auswertung der Tweets zum Educamp versuchen. Für irgendetwas müssen die Tweets doch auch nach ihrer Mindesthaltbarkeit zu gebrauchen sein. Ausserdem ist es ein Versuch, die Halbwertszeit der Tweets zum #ecco12 mindestens zu verdoppeln.Weiterlesen
Herr der eigenen Daten sein
Das Thema Selbstvermessung lässt mich nicht los. Je mehr ich dazu recherchiere um so mehr bekomme ich das Gefühl, dass die Daten eines einzelnen Nutzers relativ unspannend sind. Erst das Aggregat vieler Daten lässt interessante Korrelationen zu. Ob die dann immer stimmen oder nicht ist dann eh Teil des statistischen Unsinns. Menschen lassen sich eben nicht auf Zahlen reduzieren und wird es doch gemacht, kann nur ein Ausschnitt der Persönlichkeit reflektiert werden. Wir können zwar mit Wortwolken Häufigkeiten genannter Worte ausrechnen, wenn jedoch das Ergebnis „der, die, das, für, und, ist, mit“ ist, hat man es nicht gerade mit sinnstiftenden Interpretationen zu tun. Dennoch, Selbstvermessung ist mehr als nur etwas über sich selbst zu erfahren. Es hilft mein digitales Gedächtnis zu archivieren, denn unbegrenzte Datenspeicherung ist umstritten, zurecht. Für mich persönlich kann sie aber Teil meiner Konstruktion von Welt sein. Früher habe ich Tagebuch geschrieben, wenn ich heute die damals geschriebenen Zeilen lese, helfen sie meiner Erinnerung auf die Sprünge. Aber wann schaut man auf diese Datensammlung zurück, es ist angesagter, nach vorne zu schauen.
Als Pädagoge frage ich mich, welche Erkenntnisse die hinterlassenen Daten neben der Selbstvermessung noch ermöglichen:
- Sensibilisierung für die Menge der hinterlassenen Spuren.
- Verhältnis von Privat und Öffentlich definieren.
- Die Nutzung der hinterlassenen Daten nicht nur Anderen überlassen.
- Gesamteindruck vom digitalen Ich gewinnen.
- Meine Daten sind nie von denen meiner „Freunde“ zu isolieren. Viele Daten geben auch Informationen über mein Netzwerk preis.
Wer mit Teilnehmenden seiner Seminare einmal Daten vor dem Hintergrund der genannten Punkte auswerten will, dem seien folgende Tools empfohlen. Es sei aber auch darauf hingewiesen, dass die Nutzung dieser Werkzeuge den Anbietern Zugriff auf eure Daten ermöglicht:
Twitter-Vermessung:
Tweetsheet

CC by 3.0 by gibro
Mit Tweetsheet von Vizify können Tweets von Twitter ausgewertet werden. Natürlich gibt es zahlreiche Tools, die ähnliches machen, aber nur sehr wenige, die auf die letzten 3200 Tweets zurückgreifen. Häufig werden nur die letzten 500-1000 Tweets ausgewertet. Bei meiner Postingfrequenz kann ich so auf das letzte Jahr zurückschauen. Eine ähnliche Auswertung habe ich mir zwar schon mit einem Calc-Sheet zusammengebastelt, aber mit diesem Werkzeug geht das innerhalb weniger Minuten.
Mapize
Mapize ist ein Contentmanagment System für ortbasierte Informationen. Im Ergebnis werden ortsbasierte Informationen visualisiert. Bisher können Twitter Freunde und Follower und Fourquare Aktivitäten abgebildet werden. Leider ist der Datenbestand noch statisch. D.h. man kann Daten einpflegen, aber sie werden nicht in Echtzeit aggregiert. Die Möglichkeiten sind mit entsprechenden Programmierkenntnissen sicherlich recht beeindruckend. Ein Beispiel dafür ist die openinnovationmap.
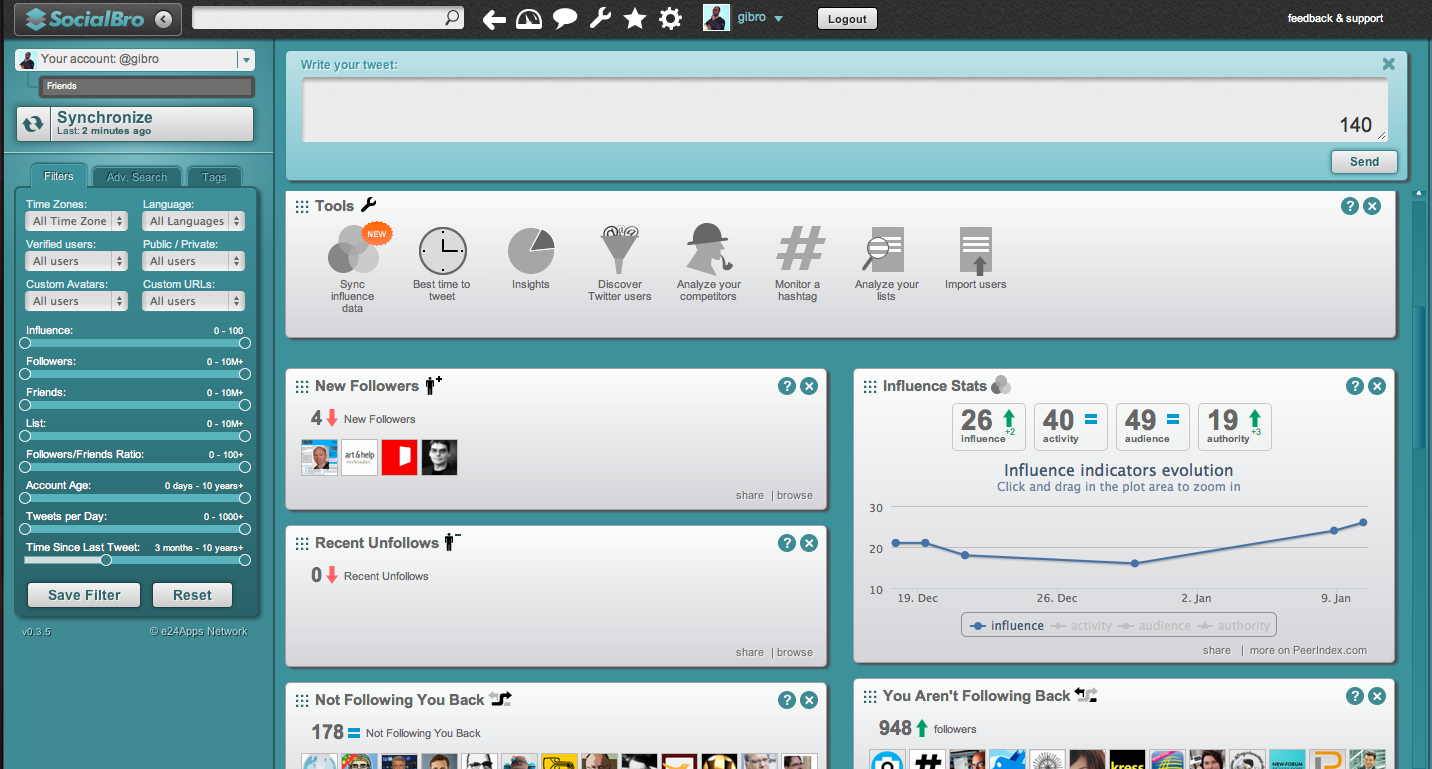
SocialBro

CC by 3.0 by gibro
SocialBro gibt es im Chrome Store. Ich hatte es vorher als Software für den Mac. Aber im Browser ist es noch schicker. Es wertet Twitter so vollständig aus, wie kein anderes mir bekanntes Tool. Dabei steht nicht mein eigenes Profil im Mittelpunkt, sondern das meiner Friends und Follower. So können z.B. inaktive Accounts schnell gefunden und entfolgt werden. Es hilft ein wenig beim Frühjahrsputz.
Facebook-Vermessung:
Openbook

CC by 3.0 by gibro
Eine Suchmaschine für Facebook, die auch funktioniert, wenn man nicht bei Facebook angemeldet ist, weil sie alle Informationen ausliest, die öffentlich in Facebook stehen und prinzipiell Jedem zugänglich sind. Mit openbook lässt sich kontrollieren, ob Informationen, die mit den Freunden getauscht wurden auch wirklich nur von denen gelesen werden können, oder die eigenen restriktiven Einstellungen einem Relaunch der Privacy-Einstellungen zum Opfer gefallen sind.
Facebook-API

CC by 3.0 by gibro
Eine API ist eine Schnittstelle für Programmierer. Damit werden Daten aus einem Web-Dienst abgegriffen und für die eigene Dienstleistung verwand. So stellt Facebook seine API den Werbetreibenden zur Verfügung, um profilbasierte Werbung einspielen zu können. Welche Daten, eben auch Private über die API ausgespuckt werden, kann man sich mit Hilfe des Angebots anschauen. Nachdem die User ID ermittelt ist, lassen sich alle Daten auslesen. Sieht nicht besonders schick aus, zeigt aber dennoch eindringlich, was Dritte auch ohne dein Einverständnis an Daten herunterladen können.
TouchGraph

CC by 3.0 by gibro
TouchGraph ist eine Facebook App, die im Gegensatz zum Social Graph mehr Möglichkeiten zulässt, die Auswertungen zu spezifizieren. TouchGraph gelingt es auch sehr gut, die einzelnen Netzwerke innerhalb meiner Freundesliste voneinander abzugrenzen. Abgesehen davon sieht es am Ende auch noch schick aus.
Profil Analysis

CC by 3.0 by gibro
Auch das ist eine Facebook App, mit der das eigene Profil gescannt wird. Danach wird ein Score für dein Profil errechnet. Besonders viele Punkte habe ich für die Menge an Posts im Vergleich zum Durchschnitt bekommen. Wenn auch die Software zu dem Schluss kommt, ich sei ein durchschnittlicher Facebook-Nutzer im Vergleich zu meinen Freunden, so liegt das nur am Mittelwert. Schaut man sich die einzelnen Werte an, so liege ich entweder weit drunter oder weit drüber. Je mehr Werte also einbezogen werden, um so durchschnittlicher sind wir alle.
Archiv:
Memolane

CC by 3.0 by gibro
Diese Timeline ist in der Lage viele gängige social Networks anzuzapfen, darüber hinaus kann man beliebig viele RSS-Feed einrichten. Es entsteht ein digitales Archiv. Das schon einige Jahre in die Vergangenheit reicht. Entscheidend ist, dass Memolane die Daten nicht bei sich speichert, sondern von den eingestellten Diensten abruft. Werden die Daten gelöscht, sind sie auch bei Memolane nicht mehr zu sehen. Der Rückblick in die Vergangenheit ist interessant, bedeutet aber auch, dass viele deiner Daten sorgsam gehütet werden.
Selbstvermessung


CC by-nc-nd 2.0 by evilnick (flickr)
Der Titel des Beitrags entstammt einem Beitrag beim elektrischen Reporter. Über die Kommentare des Youtube Videos bin ich auf einen Artikel beim Spiegel zu diesem Thema gestoßen:Digitalisierung des Ich. Die dort beschriebene Selbstvermessung hat jedoch nicht so viel mit dem zu tun, wie ich den Begriff ausgelegt habe. Ich habe nur die Devices, mit denen Daten erhoben werden erweitert. Es ist nicht das Blutdruckmessgerät oder die Fettanalysewaage, sondern die Logfiles, die im weitesten Sinne durch die Nutzung digitaler Dienste anfallen.
Google weiss mit Sicherheit mehr über uns, als wir selbst. Das sich die Konzerne selbst um unsere Privatsphäre bemühen sollten steht wohl kaum in ihren AGBs. Warum auch, sie verdienen mit unseren Daten Geld, aber anders, als sich Tante Inge das vorstellt. Es geht natürlich nicht um meinen Datensatz, sondern um Millionen von Datensätzen, die miteinander in Beziehung gestellt werden. Was ich im Rahmen meiner persönlichen Jahresabschluss-Vermessung versuche ist ja das genaue Gegenteil: es geht nur um meine Daten und nicht die der aggregierten Masse.
Natürlich bieten uns die Dienste selbst kaum Möglichkeiten unser Daten auszuwerten. Allen voran Facebook, aber auch Twitter und Google geben nicht gerade freiwillig die gewollten Daten heraus und wenn dann nur häppchenweise. Bei Facebook ist fast unmöglich an die eigenen Daten zu kommen, zumimdest so, dass man sie jenseits eines pdfs in einer verarbeitbaren Form bekommt.
Beim lesen des Artikels kann man sich fragen, ob ich mich nicht schon längst von meiner Privatsphäre verabschiedet hätte. Bei den Auswertungen ist mir aber klar geworden, dass ich bei den meisten hier veröffentlichten Informationen eher eine Distanz zu meiner Person feststelle. Es sind Zahlen, die mich und mein Leben in 2011 quantitativ vermessen. Was hier nicht zu finden ist, ist eine qualitative Analyse für 2011. Wenn Jeff Jarvis behauptet, ins Internet gehören keine privaten Daten, dann würde ich ihm wiedersprechen. Weil es durchaus bei unterschiedlichen Datensätzen zu Korrelationen führen kann, die viel über mein „Privatleben“ aussagen, wie die preisgekrönte Auswertung der Verbidungsdaten von Malte Spitz gezeigt haben.
Dennoch, was heiß hier Privat? Für mich ist es ein mich umgebender Raum, der durch das Internet zwar löchrig wird, aber immer noch von mir selbst definiert wird. Wo ich wohne ist seit ewigen Zeiten dem Telefonbuch zu entnehmen, wie es bei mir in der Wohnung aussieht, geht nur wenige etwas an. Privat sind auch meine Krankheiten, meine Familie und meine sexuellen Vorlieben. Dazu wird man im Internet bisher nichts finden. Daran wird auch die Auswertung meines Google Webprotokoll (noch) nichts ändern.
Kommen wir im Einzelnen zu den Daten, die ich ausgewertet habe:
Google Latitude

CC by 3.0 by gibro
Bei Google Latitude gibt es zwar ein Dashboard, das greift aber nur auf die Daten der letzen 30 Tage zurück. Es hat mich einen ganzen Abend gekostet manuell kml-Dateien der letzten 12 Monaten abzuspeichern. Danach lassen sich aber sehr schöne Ergebnisse erzielen:
Insgesamt habe ich in 2011 65.720 km zurückgelegt. Im März (Barcelona) und im September (Bregenz) habe ich die meisten Kilometer zurückgelegt.
Laut Dashboard der letzten 30 Tage war ich ca. 53% meiner Lebenszeit zu Hause, 47% der Zeit habe ich mit Arbeiten im weitesten Sinne verbracht. Davon ca. ein Drittel in meiner Arbeitsstelle in Hattingen und die anderen zwei Drittel unterwegs, jenseits von Hattingen. Mein Arbeitsplatz ist mobil geworden, seitdem ich mit Handy, Tablet und Laptop ausgestattet bin, sind die Anforderungen an die Arbeitsumgebung drastisch gesunken. Solange es warm und trocken ist und eine Internetverbindung zur Verfügung steht, steht einem produktivem Output nicht entgegen.
Wenn man alle kml-Dateien zu einem Film zusammenkopiert, sieht das so aus:
Google Suche

CC by 3.0 by gibro

CC by 3.0 by gibro
Bei Twitter gibt es zumindest eine gute API, so dass bei Einrichtung des richtigen Dienstes, bei mir ist das backupmytweets.com, die Daten in den gewünschten Formaten ausgespuckt werden. 2011 habe ich 2706 Tweets geschrieben, 264.419 Zeichen, bzw. 38038 Worte. Das macht 97 Zeichen bzw. 14 Worte pro Tweet im Durchschnitt. In allen Tweets bringe ich es insgesamt auf 1893 Replies und 1013 Links.
Oben sind die Tweets pro Monat zu sehen. Besonders hohe Werte gab es im Februar, März, April und November. Der erhöhte Twitterbedarf läßt sich mit besonderen Veranstaltungen erklären: Im Februar die #kasnetzkultur11 , eine Veranstaltung der Konrad-Adenauer-Stiftung zu Netzkultur, im März #kbom11 (Keine Bildung ohne Medien) bzw. die spontane Ergänzungsveranstaltung #kmob11, im April die #rp11, die Republica 2011 und im November die #kasdk11, eine Veranstaltung der Konrad-Adenauer-Stiftung zu digitaler Kultur. Wer jetzt meint, daraus ablesen zu können, dass ich ein großer Sympatisant der CDU wäre hat sich geirrt. Das bin ich keineswegs, aber wer glaubt schon, dass Daten allein etwas über einen Menschen und seine Privatsphäre aussagen.
Ich habe die Tweets auch mit Manyeyes.com ausgewertet:
Google Mail

CC by 3.0 by gibro
Insgesamt sind 18.493 Mails in meinem Postfach eingetroffen. 2748 waren von Twitter, sie haben mich daran erinnert, wenn mich jemand erwähnt hat, mir eine DM geschrieben hat oder mir gefolgt ist.Später im Jahr wurde die Benachrichtigung für Retweets hinzugefügt. Die habe ich auch nicht abgestellt. 4291 Mails sind in meinem gesendet Ordner gelandet. 2350 Mails gingen an meinen Bildungswerksaccount oder wurde von diesem verschickt. Es handelt sich in der Regel um die interne Kommunikation mit dem DGB Bildungswerk.
Google Calendar
Ich frage mich, warum es keine Software gibt, um den eigenen Kalender auszuwerten. Was macht Google damit? Interessiert denn niemanden, wieviel Zeit man im Jahr wie verplant hat? Über Hinweise freue ich mich in den Kommentaren.
Rückblick und Auswertungen zum Barcamp des AdZ #adz11

Der Begriff Reformpädagogik muss ersetzt werden, nicht nur weil die Missbrauchsfälle unweigerlich mit dem Begriff verbunden bleiben werden, sondern auch, weil er nicht mehr zeitgemäß ist. In der Wikipedia ist zu lesen: „Dem Begriff Reformpädagogik werden verschiedene Ansätze zur Reform von Schule, Unterricht und allgemeiner Erziehung zugerechnet, die – oft zurückgehend auf Comenius, Rousseau und Pestalozzi – eine Pädagogik vom Kinde her vertreten.“ Alle dort genannten Vordenker kannten die heutige Gesellschaft nicht. Weiterlesen
Warum es Google+ als Mainstream Network schwer haben wird


Im Gegensatz zu den vielen Artikeln, die Google+ und seinen Ansatz für ein soziales Netzwerk schön reden, ihm sogar eine Konkurrenz zu Facebook aufschwatzen wäre ich nach allen bisherigen Versuchen (Orkut, Wave, Buzz) von Google in diesem Feld skeptisch. Klar wurde mir das aber erst nach dem Lesen der letzten Spiegel-Kolumne von Lobo.Weiterlesen
Informationen brauchen einen Behälter #opco11


CC by-nc-sa gibro
Informationen brauchen einen Behälter heißt es im Titel. Damit ist nicht nur der Aggregatzustand gemeint, in dem die Information vorliegt, sondern auch ihre Darstellung und ihr Zusammenhang. Das ist nicht nur eine Frage des technischen Filters (wie z.B. RSS, Facebookgruppe, Gruppen und Hashtags bei Twitter oder Diigo), sondern auch eines des individuellen Filters. Wenn ich mich selbst bei der Rezeption meines Google Readers beobachte, stelle ich fest, dass Zeit eine ganz wichtige Rolle spielt. Mein Reader wird immer aufgelesen, dort sammeln sich nicht tausende ungelesener Beiträge, sondern es ist wie bei vielen E-Mail Programmen immer aufgeräumt, deshalb spielt Zeit auch eine Rolle. Das mag eine Schwäche sein, aber so ist das mit den Gewohnheiten,mit diesem Ordentlichkeitsfimmel ist eher die Sorge verbunden etwas zu verpassen. Weiterlesen
Twitterspiele

 Twitter und Facebook lassen sich nach wie vor schwer erklären. Wer es nur gezeigt bekommt, kann sich kein Bild machen und wer es selbst einmal probieren will gibt schnell auf, weil es den Erwartungen nicht entspricht, weil es kein Newerk per default gibt, sondern die persönliche Umgebung in mühevoller Kleinarbeit über Wochen und Jahre organisch entstehen muss. Die Lust an der Gärtnerei entsteht auch nicht in den ersten 4 Stunden, sondern, wenn man die Früchte seiner Arbeit Monate später einfahren kann. In sofern ist es schwer in einer Seminarsituation, in der häufig nicht mehr als 2 Stunden Zeit bleiben einen sinnvollen Enblick in ein Social Media wie Twitter zu geben.
Twitter und Facebook lassen sich nach wie vor schwer erklären. Wer es nur gezeigt bekommt, kann sich kein Bild machen und wer es selbst einmal probieren will gibt schnell auf, weil es den Erwartungen nicht entspricht, weil es kein Newerk per default gibt, sondern die persönliche Umgebung in mühevoller Kleinarbeit über Wochen und Jahre organisch entstehen muss. Die Lust an der Gärtnerei entsteht auch nicht in den ersten 4 Stunden, sondern, wenn man die Früchte seiner Arbeit Monate später einfahren kann. In sofern ist es schwer in einer Seminarsituation, in der häufig nicht mehr als 2 Stunden Zeit bleiben einen sinnvollen Enblick in ein Social Media wie Twitter zu geben.
Meine Idee: Weiterlesen
Verspäteter Jahresrückblick

 Ich habe ewig gesucht, bis ich ein vernünftiges Werkzeug gefunden habe, um meine Tweets des letzten Jahres auszuwerten und somit ein wenig zurückzuschauen. Ich habe alles durch von Tweetbackup über Tweetake bis Twitterbackup. Im Prinzip habe ich alle Empfehlungen des Blogbeitrags zu „How to Backup your Twitter Archive“ durch, alles scheint im Moment im Relaunch versunken. Das einzige halbwegs funktionierende Tool war Backupmytweets. Damit ist man zumindest in der Lage die letzten 3200 Tweets zurückzuholen. Auch wenn man anschließend in 500-er Päckchen die Daten herunterladen muss, weil der Archive-Download gerade nicht funktioniert. Nach 1h Datennachbereitung konnte ich folgende Daten erheben:Weiterlesen
Ich habe ewig gesucht, bis ich ein vernünftiges Werkzeug gefunden habe, um meine Tweets des letzten Jahres auszuwerten und somit ein wenig zurückzuschauen. Ich habe alles durch von Tweetbackup über Tweetake bis Twitterbackup. Im Prinzip habe ich alle Empfehlungen des Blogbeitrags zu „How to Backup your Twitter Archive“ durch, alles scheint im Moment im Relaunch versunken. Das einzige halbwegs funktionierende Tool war Backupmytweets. Damit ist man zumindest in der Lage die letzten 3200 Tweets zurückzuholen. Auch wenn man anschließend in 500-er Päckchen die Daten herunterladen muss, weil der Archive-Download gerade nicht funktioniert. Nach 1h Datennachbereitung konnte ich folgende Daten erheben:Weiterlesen
Echtzeit: Twitter und Bildung
{kind=link}
In vielen unterschiedlichen Formaten haben wir in den letzten Jahren mit öffentlicher Bildung experimentiert. Wir haben Twitterwalls für nicht öffentliche Veranstaltungen konzipiert, wir haben von anderen Veranstaltungen öffentlich getwittert. Wir haben TwitterwallsWeiterlesen